

You probably benefit from file compression every day, even if you don’t realize it. But just what does file compression mean, and how is it used with computers and online?
Here we explain the basics of file compression, discussing the two main types and providing common examples.
The Basics of File Compression
In one sentence, file compression is the act of taking some amount of data and reducing its size while still maintaining the integrity of the information. This is useful because it allows us to store smaller files on storage disks, as well as making file transfer over the internet more efficient.
At first glance, it might sound impossible to make something smaller while still essentially keeping it the same. Let’s look at the two main types of compression to illustrate how it works.
Lossy Compression
Lossy compression reduces the size of a file by throwing out pieces of information that aren’t necessary. In forms of data like images and music, you don’t need every single bit of data present to enjoy the source media.
Consider an MP3 file, which is a popular lossy format for audio. Compared to the original recording, an MP3 file of a song won’t have all the exact highs and lows. But this isn’t a problem (to a point), because humans can’t hear certain sounds anyway.
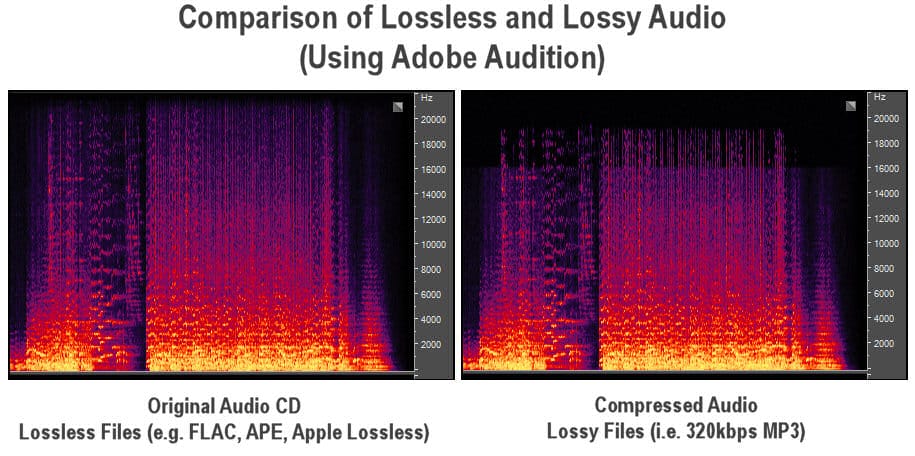
By removing the frequencies that we can’t perceive, you can make the file smaller without having a noticeable effect on quality. This makes it more suitable for storing on a portable device, so you can keep lots of tracks on it.
Another well-known example of a lossy file type is JPEG, an image format. A high-quality image taken with a professional camera in RAW format might take up something like 25MB. For printing professional posters or something similar, you’d want to use the original image for the best quality.
However, say you wanted to share the photo with your friends on Facebook. Most people probably don’t care about the minute details of the image, so compressing it into a JPEG is good enough.
Image compression combines similar nearby colors to shrink the file size. For example, instead of using a dozen shades of brown for the sand in a picture of the beach, it might reduce this to just a three or four shades. Storing fewer colors uses less space for the image.
When Lossy Compression Goes Too Far
Lossy compression isn’t a perfect solution, though. The file quality can drop significantly when you compress something too heavily, or compress it multiple times.
You can hear an example of this in the below video showing the effect of compression on audio. As the video slowly applies more and more compression to the sounds, it plays the leftover pieces each level of compression removed. While impossible to hear at first, the heaviest compression takes out major pieces of the track.
It’s also easy to spot overly compressed images. When you save in JPEG format, most image editors allow you to choose a quality level from 0-100. Reducing the quality from 100 to 90 or 80 is an easy way to create a smaller file with no major differences. But if you drop this too low, the compression becomes noticeable; you’ll see artifacts around the areas where colors meet.
An example of this is below, showing an original image on top and a preview of a 10% quality JPEG below. Notice the poor quality around the woman’s elbow and where her hair meets the background.
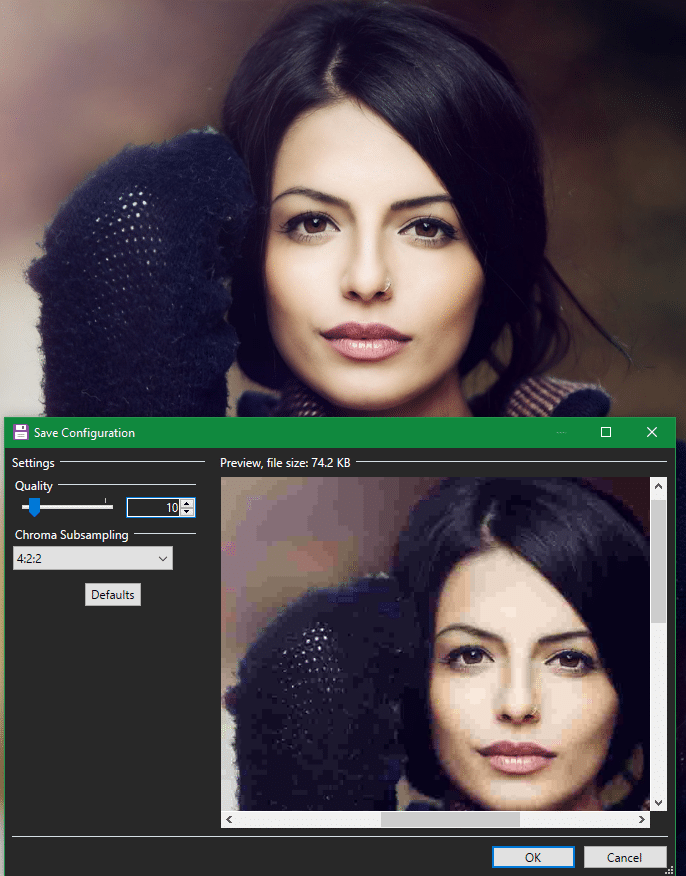
In summary, lossy compression is the right choice when an approximation of the original data is good enough. But using it removes data that you can’t get back.
Lossless Compression
Lossy compression doesn’t work in all cases. When all the data in a file is critical, such as a spreadsheet, you can’t just throw some information out or it would become unreadable. That’s where lossless compression comes in.
Lossless compression allows you to reduce the size of a file without removing anything. In essence, this works by removing redundancy so the storage of the data is more efficient.
Consider a text file that contains the following string of characters:
aaaaaaaabbbbbbcccddddddd
Using “compression”, we can rewrite this with numbers showing how many of each letter appear in a row. It would thus look like this:
a8b6c3d7
This is a form of lossless compression, because it allows us to recreate the original text exactly. While the original string took up 24 characters, the compressed version only has 8. That’s a 67% reduction in file size, which is significant.
Of course, this is a basic example; the actual mechanics for lossless compression algorithms are much more complex. You’re probably familiar with common lossless formats, such as PNG images and FLAC audio.
ZIP Files
Another common lossless format is ZIP, which is supported by nearly every modern operating system. ZIP is known as an archive file format, because it collects multiple files into one unit.
In addition to compressing files to save space, ZIP files also come in handy when you want to send an entire folder’s worth of files to someone. You can’t send the whole folder by email or other methods, and sending the files one-by-one is cumbersome. Thus, you’ll often find ZIP files when downloading software and other media from the internet.
In Windows, you can right-click on any existing folder and choose Send to > Compressed (zipped) folder to make a ZIP file without any extra software.
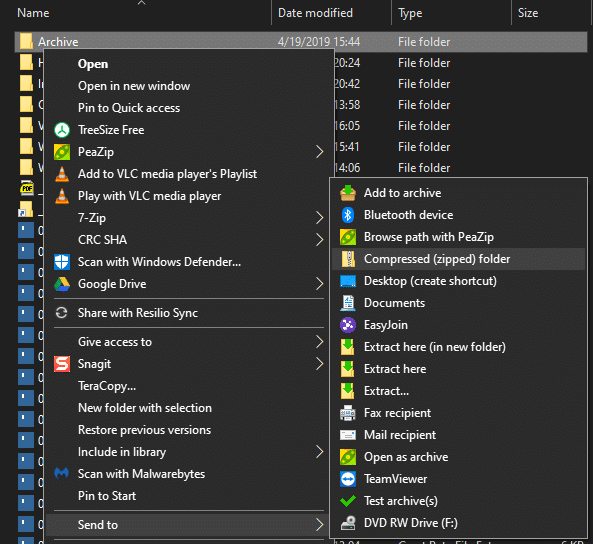
In summary, lossless compression is the right choice when you need a complete replica of the original file. But using it results in a larger file size than lossy compression.
Using Both Forms of Compression Together
There’s no “best” form of compression, as the right choice depends on your usage. Often, they can even work together.
For example, say you want to digitize an old CD so you have a copy on your computer. When you perform the initial CD rip, you should save it in a lossless format like FLAC. These “master copy” files will be as good as the CD you ripped them from.
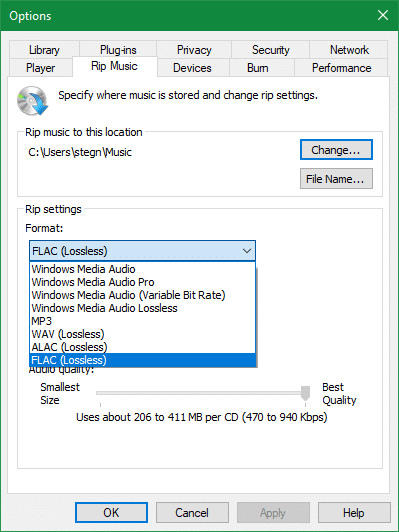
Afterward, you can convert those FLAC files to MP3 and put them on your phone for listening anywhere. While the MP3 files aren’t a perfect version of the CD audio, they’re good enough for, say, listening while you jog. And the MP3 files are much smaller than the FLAC ones.
For conversion purposes, you should generally only convert lossless formats to lossy. Converting lossy formats to lossless is a waste of space, because you can’t recover the information that the lossy compression removed. And converting lossy formats to other lossy formats will continue to throw out data until the file is unrecognizable, as we heard above.
Compression Is a Vital Process
Now you know the essentials of compression. Next time you see a blurry JPEG image, you know exactly what happened to it. And you can make better decisions about what kinds of compression and file formats to use.



